Parcel 2 beta 1
📦 Parcel 2 beta 1 - improved stability, tree shaking, source map performance, and more! 🚀
The Parcel team is super excited to release the first beta of Parcel 2 today! This marks the first Parcel 2 release that’s more stable than our nightly and alpha releases, and our commitment to avoid changing most user facing APIs. Please try it out and give us your feedback on GitHub!

It’s been a while since our last alpha release, and there has been a ton of active development on Parcel 2 in the meantime. We’ve been focusing on stability, performance, and reliability as we prepare for our stable v2 release, but we’ve managed to sneak in a few new features too!
-
🌳 Improved tree shaking — Parcel’s tree shaking implementation has improved tremendously since the last alpha release. In addition to a ton of bug fixes and performance improvements, Parcel 2 now produces source maps for tree shaken bundles, and displays friendly error messages when you reference an unknown symbol.
-
🗺 Faster source map generation— Parcel now has a brand new source map module, hand tuned for our specific usecases. It’s written in C++ for performance, and is ~20x faster at combining source maps from multiple files!
-
#️⃣ Improved content hashing— Parcel now has more reliable content hashing support for long term cacheability of bundles. In addition, Parcel 2 now avoids cascading invalidation by only updating a manifest in entry bundles rather than all referencing bundles.
-
🚨 Resolver diagnostics— Parcel 2 now supports friendly error messages when it cannot find a module you’ve referenced in your code. These include a detailed code frame showing where the error occurred, along with suggestions on how you might be able to fix the issue.
-
📊 More accurate bundle reports— The bundle reports that Parcel generates in your CLI at the end of a production build are now more accurate. They are now based on source maps, and exclude code that has been removed during tree shaking and minification for more accurate file sizes.
-
🐞 Tons of bugfixes and improvements — This release includes countless bugfixes and stability improvements. The team has been working hard on testing Parcel 2 against some very large applications, and we’re excited to see how it works for you.
Tree shaking
#Building a production JavaScript compiler is extraordinarily challenging. We’ve been working on Parcel’s tree shaking implementation since 2018, and it has improved tremendously since then. Parcel 2 enables tree shaking by default, and we’ve recently been using it to deploy some very large applications in production at Atlassian and Adobe.
Parcel’s tree shaking implementation is unique among bundlers. Aside from supporting ES modules as many other tools do, Parcel also supports tree shaking CommonJS natively. While some libraries are now offering ES modules, most of the code on npm is still written in or transpiled to CommonJS before it is published. CommonJS can be difficult to statically analyze, like much of JavaScript, and we’ve put a huge amount of effort into making this transparent. We can statically analyze in a majority of cases, and automatically bail out and wrap the module in a function when it performs unsafe operations. We’ve discovered and fixed many bugs and edge cases in our tree shaking implementation over the last few months, and tested it extensively. We’d love to hear how it works on your application! Please report any bugs you find.
Parcel now generates source maps for tree shaken bundles as well. This was a limitation since the initial tree shaking release, and a major challenge for us. Since tree shaking does not simply concatenate files together linearly, it was difficult to combine source maps in the correct way. Instead, we now store ASTs in our cache, and combine them together instead. This preserves location information as part of the AST nodes, which can be used to generate a final source map at the end as part of code generation.
In addition to source maps, location information also allows us to give more accurate error messages. We are now able to show detailed code frames for errors such as importing a non-existent export from a module and more.
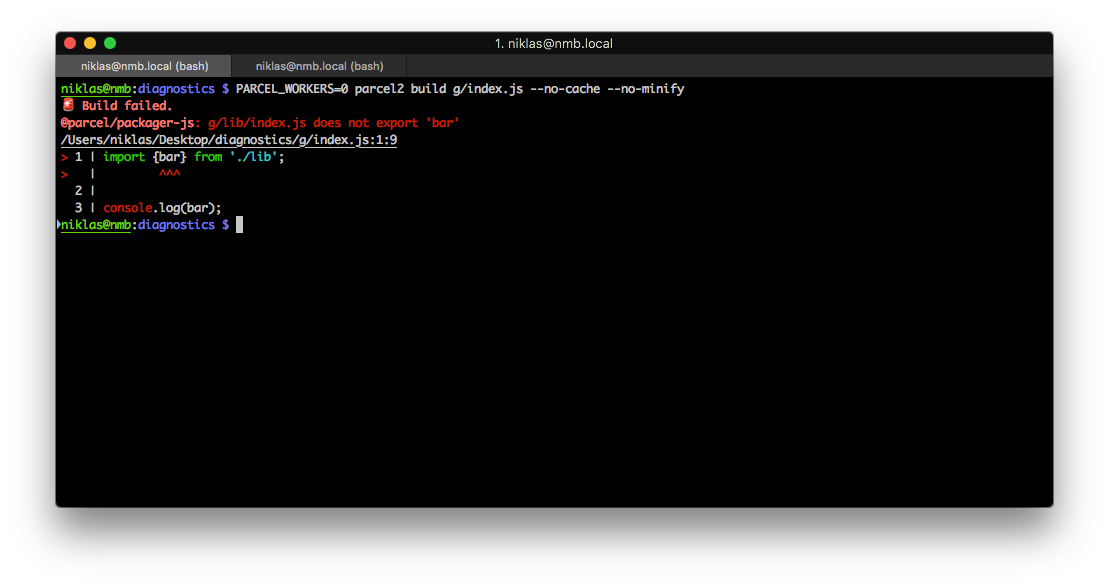
HUGE thanks to Niklas Mischkulnig for all of his work on improving the tree shaking compiler in Parcel. 🙏
Source maps
#Source maps can be quite CPU and memory intensive to generate, especially when combining source maps from many files. We previously used the Mozilla source-map library to do this, but ran into performance issues on large bundles.
To address this, we’ve implemented our own library for combining and manipulating source maps. It’s a native node module, written in C++, that’s purpose-built for Parcel’s use cases. It utilizes FlatBuffers for serialization between workers and to the cache, which dramatically reduces the cost of generating and parsing that we had previously seen with JSON. Overall, it’s ~20x faster than the JavaScript implementation at combining source maps together. As an example, a bundle that previously took 3 seconds to generate the source map now takes just 175ms!
In addition to the native node module, there’s also a Web Assembly build of the same library, which allows it to be used in environments like web browsers. While not as fast as the native bindings, it’s exciting that the same code can be reused rather than needing to maintain a pure JS implementation as well.
Thanks to Jasper De Moor for all of his amazing work on source maps in Parcel! 🥳
Content hashing
#We have supported long term caching in Parcel via content hashed file names since v1.7.0. These content hashes have historically been generated by hashing each individual file contained within the bundle. This ensured that changes to any file in the bundle caused the file name to update, and invalidate browser and CDN caches. However, it did not take into account cases where Parcel runtime code itself changed, rather than source code. This could happen when upgrading the version of Parcel, or a plugin that ran later (e.g. a minifier).
Parcel now generates hashes based on the final content of the bundle, after all packaging and minification has been done. This means that even if runtime code injected by Parcel changes, or your minifier changes the way it compiles your code, the content hashes will now update properly.
This was a challenge to implement, because bundles may reference other bundles as part of the code. Since the final names won’t be known until after the code has been generated, Parcel now inserts placeholder references into the content of the bundle, rather than the final bundle names. At the end, these are replaced with the final names as they are being written to disk.
In addition to more reliable content hashing, Parcel now avoids the cascading invalidation problem in many cases. This issue is well covered in the blog post linked above, but essentially since bundles may reference other bundles by content hashed file names, when a leaf bundle updates, all of the bundles leading to that bundle must also update in order to bust the cache. This leads to sub-optimal cache performance.
Instead of directly referencing bundles by full content hashed name, Parcel now includes a manifest in each entry bundle. This manifest includes a mapping of stable bundle ids to final content hashed filenames. Rather than referencing other bundles directly, only the bundle id is included. When a bundle further down the tree updates, invalidation no longer needs to cascade to intermediary bundles because the bundle id is stable. Only the entry bundle (containing the manifest) and the bundle that changed need to update. This can improve the cache hit rate significantly.
Thanks to Maia Teegarden and Will Binns-Smith for their work on content hashing in Parcel 2!
Resolver diagnostics
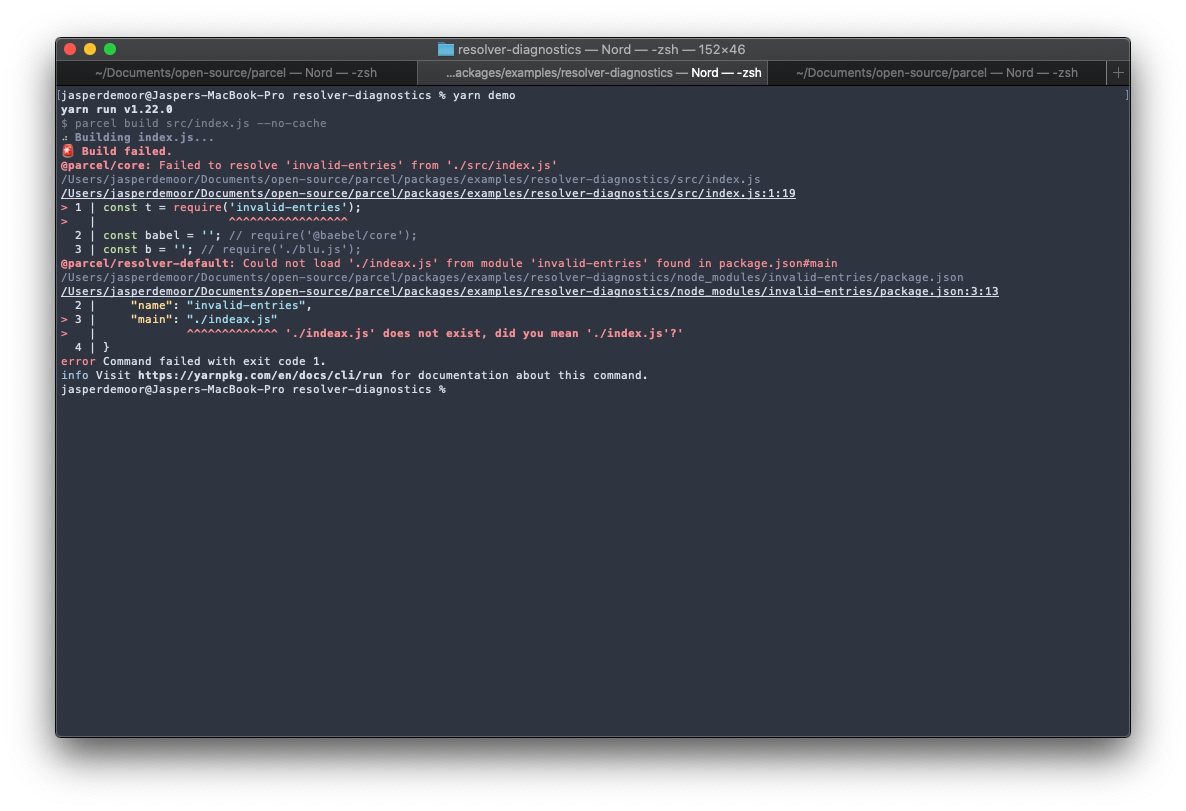
#Parcel now includes improved error reporting when it cannot find a module you’ve referenced. This includes a code frame stack showing you exactly where the error occurred, and any intermediary files that led to the issue.
For example, the below screenshot shows an error that would typically only include the first line (Failed to resolve ‘invalid-entries’ from ‘./src/index.js’) and possibly the first code frame if you’re lucky. However, this doesn’t tell you where the error actually occurred. In this case, the invalid-entries module does exist, but it points to a non-existent file in its package.json. Parcel now displays a second code frame for the package.json, pointing to the exact line that caused the underlying issue.
Upgrading
#Upgrading from the previous alpha release of Parcel 2 should be fairly straightforward, but there are a few things to be aware of.
-
Config resolution changes — Parcel now only supports a single .parcelrc config file in the root of your repository. Additional config files in sub-directories are no longer supported for performance reasons.
-
Config changes—
transformshas been renamed totransformersin .parcelrc for consistency with other plugins. -
Target resolution changes — Targets defined in package.json files within a monorepo are now resolved from the project root rather than individual packages when pointing to a file rather than the package directory itself. This means that you can point to files across multiple packages to build a single target, or point at the packages themselves to build the targets defined in each package. See the description here and here for more info.
-
Dist directory changes — by default, Parcel now outputs into the dist directory in your project root in servemode, rather than a hidden directory inside the cache. This allows you to more easily inspect the built files during development. You can override this using the
--dist-dirCLI option. -
Plugin API changes — there have been several plugin API changes. Please see the documentation, linked below, for more details.
Documentation
#We’ve been working on a new documentation website for Parcel 2! It’s still very much a work in progress, but we plan to cover everything from getting started with building a basic application or library with Parcel, to more advanced features, recipes, and building your own plugins. Please check it out and give us your feedback!
Stability
#As mentioned earlier, this is the first beta release of Parcel 2. This means it is more stable than a nightly or alpha release, but some changes are still expected before the fully stable release. In particular, beta means we are not planning on changing most user facing APIs such as configuration formats (in package.json and .parcelrc) and CLI arguments. Some changes are still expected to plugin APIs before the first release candidate, however we do not expect major changes at this point.
Try it out!
#If you’ve been waiting to try out Parcel 2, now would be a great time! You can install it by running yarn add parcel@next. If you need assistance, you can ask questions on GitHub discussions, and if you run into bugs, please report them on GitHub issues. You can also find me @devongovett on Twitter. We’re really excited to hear your feedback!